
1. 异常现象
首先在本地开发是完全没问题的与部署在服务器中连接的是同一个数据库,实测将druid监控给出的超时sql通过navicat直接执行速度非常快不存在加不加索引的问题。
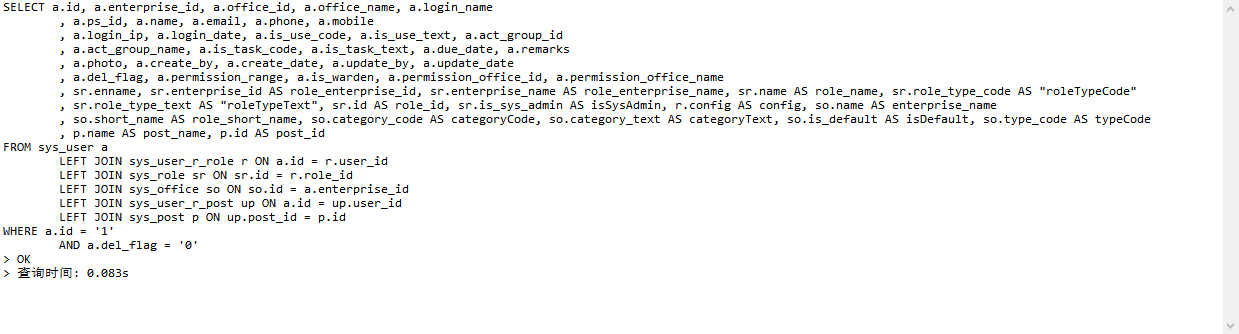
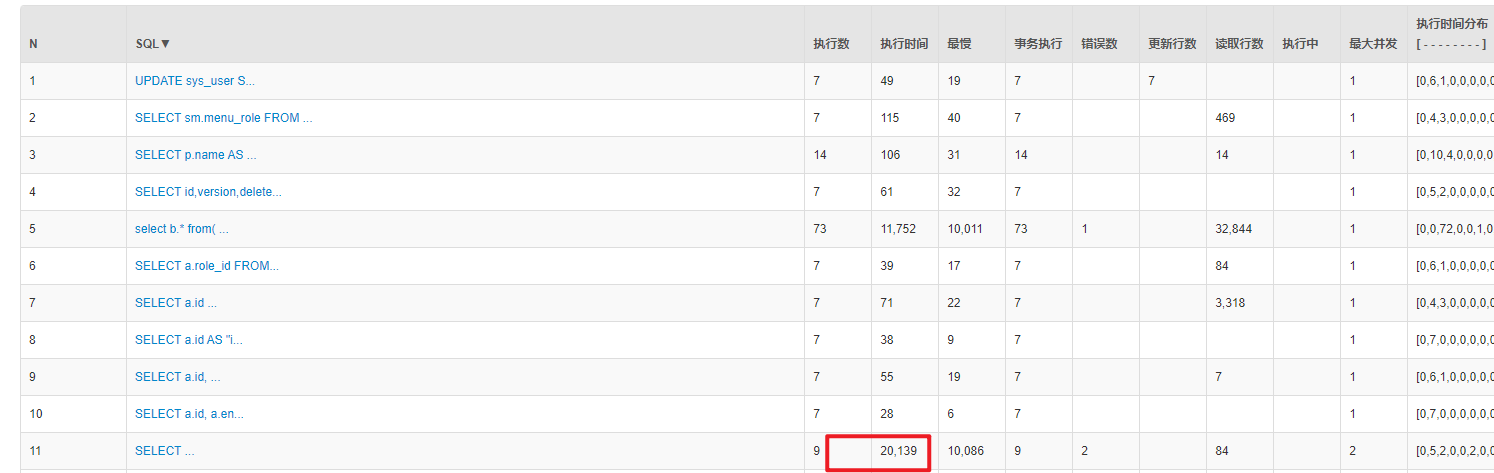
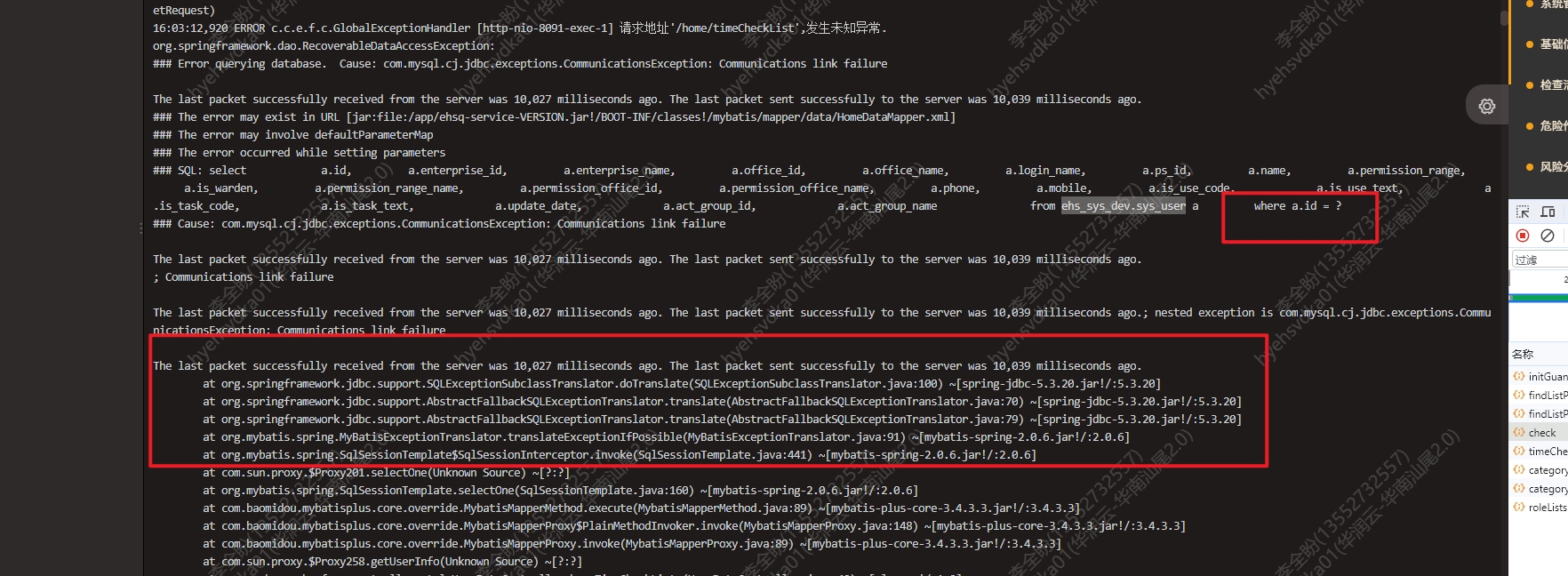
2. 解决方案
因为服务是通过jenkins来发布的,最后执行docker run -p 8080:8080的方式来进行端口映射,可能会出现某种网络问题故而尝试将网络切换成主机模式 --network=host,重新构建后问题消失了顺利解决问题,这非常诡异。
随着排查的深入最后来到了网卡的MTU上,根据排查去找云厂商反馈那边的宿主机MTU是1450,而开出来的虚拟机里面的docker MTU是1500,这种MTU不一致的致命问题才是他的问题本质,看我图上是正确的出问题的机器他的网卡的MTU是1450但是docker却变成了1500,也就说的通为什么让容器使用host就能恢复正常,此刻他就直接用ens160了而不是用docker0,
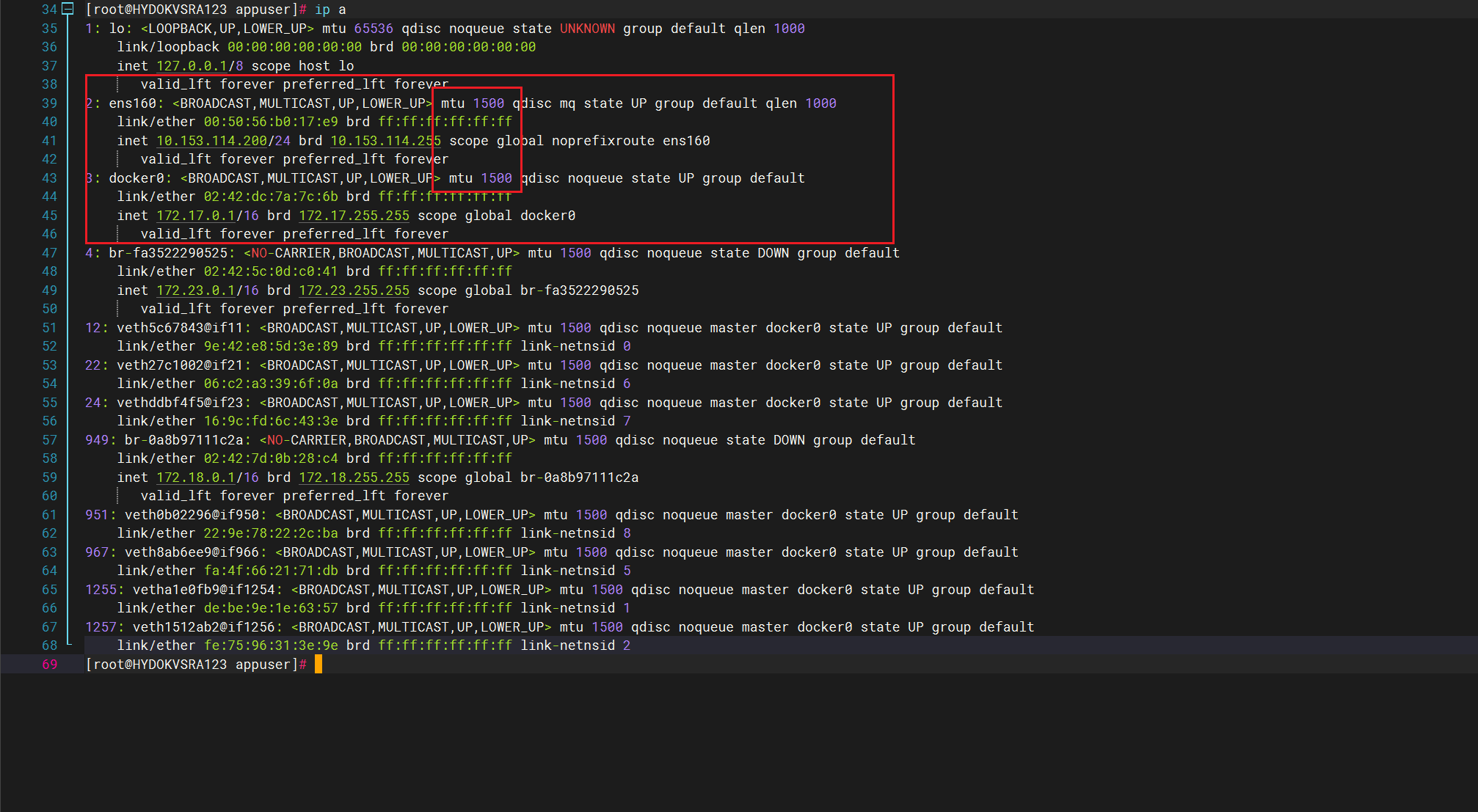
这就说明问题点真的锁定得非常准了,宿主机的物理网卡 ensxxx 是 1450,Docker 的虚拟网络接口却用了默认的 1500,这中间的 MTU 不一致就会在一些特定情况下(比如传输较大的 TCP 包、上传文件、HTTPS 请求等)导致 数据包被丢弃、重传甚至连接超时。
🧠 为什么 Docker 默认是 1500?
Docker 默认创建的 bridge 网络,其 veth 对的 MTU 是根据系统默认配置来的,通常是 1500,它不会自动感知宿主机的实际网卡 MTU,除非你手动指定。
所以只要宿主机的 ens160 是 1450(云服务商经常这么设,比如为了兼容 VXLAN、GRE 等封装),而 Docker 的 veth 是 1500,中间经过 NAT 或 bridge 转发时就会出现:
包大于 1450 就要被分片;
有的云厂商网卡或中间设备不支持分片(DF 标志设为 1);
于是就出现“能 ping 通,curl 卡死”、“http 请求无响应”这种诡异现象。
关于arm平台druid与springboot的sql超时异常
https://tanqidi.com/archives/df772298-9756-4140-b7dd-e37022d30f3c
评论